The Missing Layer Between Your Codebase and a Coding Agent
Every engineering team has a graveyard of internal improvements that never made it to the roadmap. Not because they weren't important, but because they couldn't compete with the next user-facing feature in a prioritization meeting. Documentation, coding standards, developer experience — these things matter deeply, but they're invisible to everyone except the people who suffer their absence.
In November 2025, we were watching AI tools accelerate fast. Copilot was everywhere, Cursor was gaining traction, Claude was impressive. But every time we pointed one of these tools at our codebase, the results were disappointing. Not because the models were bad, but because our codebase wasn't ready for them. The AI could write code. It just couldn't write our code.
We had a choice: keep waiting to prioritize this on the roadmap (which would never happen), or sidestep the roadmap entirely. We chose the second option. Working Group for the rescue.
Why a Working Group
A Working Group is a group of people working on a side project within the company. It lives outside the sprint. It doesn't compete for roadmap space. It runs on the energy of the people who believe the problem matters enough to show up.
We've used this format before at Decentraland and it's worked every time. The key ingredient isn't just structure — it's voluntarism. People who choose to participate bring a fundamentally different energy than people who are assigned. They work harder. They think deeper. In many cases, they put in extra hours because they genuinely care about the outcome, not because someone asked them to.
That said, voluntarism without structure produces chaos. Every Working Group we've run follows the same recipe:
- A kickoff meeting to align on the problem
- A goals document with a clear definition of done and a tracking agenda for the regular synchs
- One overall owner responsible for the WG
- Owners per task — always split the work
- A regular checkpoint to review action items, show progress, discuss doubts, and decide if it's done. Suggested no less than two weeks.
- A dedicated Slack channel for async communication on the topic only
This format has already produced some of the most impactful work at Decentraland: our first Coding Standards, the Career Ladder for engineers and managers, and the Incident Management Program. All of them started as Working Groups. All of them are still in use today.
The Mission
We framed the Working Group around one question: how can someone contribute to our codebase without getting lost, effectively using AI? This covered everything from debugging existing code to onboarding a new engineer to receiving external contributions. If an AI agent could navigate our codebase confidently, so could a person.
But it wasn't clear at first how we'd get there. In November 2025, the AI coding landscape was powerful but immature for what we needed. GitHub Copilot was widely adopted but mostly chat-based — good at autocomplete, limited at multi-file reasoning. Cursor was gaining popularity as an agent-first IDE, but its agentic capabilities were still reactive, requiring heavy user guidance. Claude was impressive in long conversations but had no Skills, no custom commands, no way to encode team-specific workflows. MCP had been published but hadn't reached mainstream adoption. Context windows were getting longer, but feeding an entire codebase into a model was expensive and often wasteful.
The tools were getting smarter. Our codebase wasn't getting any easier to understand. We decided to fix our side of the equation first. We set a recurring checkpoint every other Thursday — sync, show progress, define next steps, decide if we're done.
Goal 1: Coding Standards
We started with a simple belief: if our coding standards are solid, complete, and explicit, then any AI should be able to code like us. Not approximately. Like us.
We had standards, but they were incomplete. Some were outdated. Entire categories were missing — dapps, servers, APIs, UI libraries, tests. If a human engineer needed tribal knowledge to follow the real conventions, an AI had no chance. Moreover, different projects had evolved at different times under different teams, creating similar but conflicting local standards that made consistency even harder.
Engineers organically proposed themselves as owners. They split into small groups, each responsible for one standard category. Nobody was assigned. People picked what they cared about. After roughly three meetings and a few focus shifts, we had something we liked. Comprehensive, opinionated, and covering every type of code we write.
The more important decision was what came next: we agreed that maintaining these standards would be an ongoing effort, not a one-time artifact. We would keep them up to date as the codebase evolves, specifically to avoid having to do this again. Standards that decay are worse than no standards — they teach the wrong patterns.
Goal 2: Documentation and AI Context
With standards in place, we tested them with AI agents. The results were revealing. The agents could follow our style. They could match naming conventions, use the right patterns, structure files correctly. But they had zero awareness of what already existed in the codebase.
Style compliance is not context awareness. An AI that follows your linting rules perfectly can still produce architecturally wrong code if it doesn't understand what already exists and why. It will duplicate utilities you already have. It will create an atomic bomb in the pet shop.
Goal 2 required more cognitive load, more tasks, and more owners — one per task. We needed to document each repository we own, and we needed to do it in a structured, machine-readable way:
- A structured README for every type of software we have — dapps, servers, APIs, workers
- An AI context file per repository
- Database schemas where applicable
- OpenAPI specifications where applicable
- A GitHub Action to keep the documentation up to date automatically
With all of this in place, we were also able to improve and relaunch our documentation page using GitBook — docs.decentraland.org. GitBook was a good selection because it let us publish the standards and also integrate each repo's API specification into the public docs via GitHub Actions, keeping API docs in sync with every release. That effort was almost a side project inside the Working Group, but it came together naturally because the underlying content finally existed in a clean, structured form.
Same agreement as with the standards: maintaining these docs became a standard practice for every repository. Every update, every new repo — the documentation follows.
Goal 3: Jarvis
After a few Thursdays, we reached our Goal 2 milestone. Testing with a main workspace that had all our repos as submodules worked great for agents. We could plan big changes almost in one shot. But the setup had real downsides: a GitHub workspace with submodules is hard to maintain, hard to connect with other tools, and impossible to use without checking out every repository. There was no starting point, no index, no way to detect which repos were relevant to a task without downloading them all.
Goal 3 had to answer a clear question: how can we use everything we've built in a token-efficient way, with just plain text?
This is where @dcl/jarvis appears. Jarvis (aka Just a Really Very Intelligent System) is our knowledge library. After every repository release, a GitHub Action runs to keep Jarvis up to date. The core components are:
- A
manifest.yamlper repository with a defined structure and useful information for AI consumption - A dependency graph connecting all our repositories
- A central index — the starting point for any question
As happened with Goal 2, the team did an unexpected step up: they re-drew the entire architecture. Not because someone asked them to, but because the process of defining schemas for Jarvis forced clarity on how everything connects. The old architecture diagram was functional. The new one is a masterpiece.
Before:
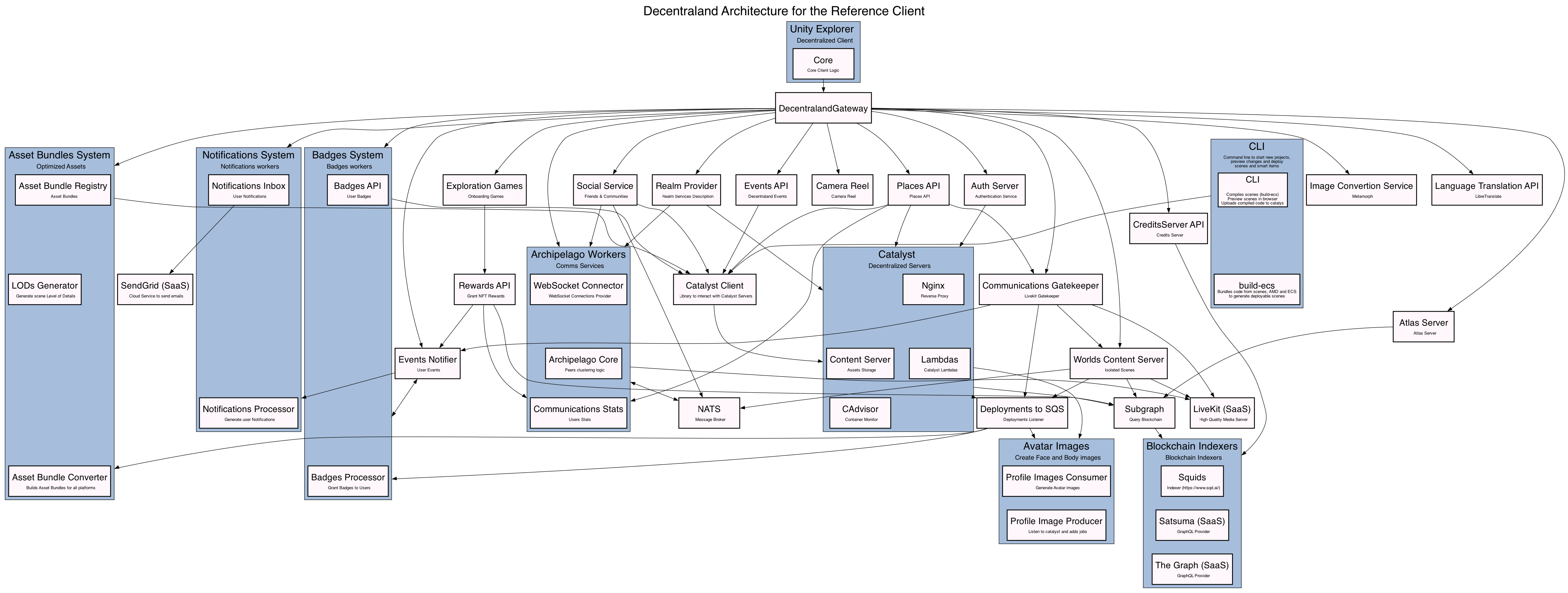
After:
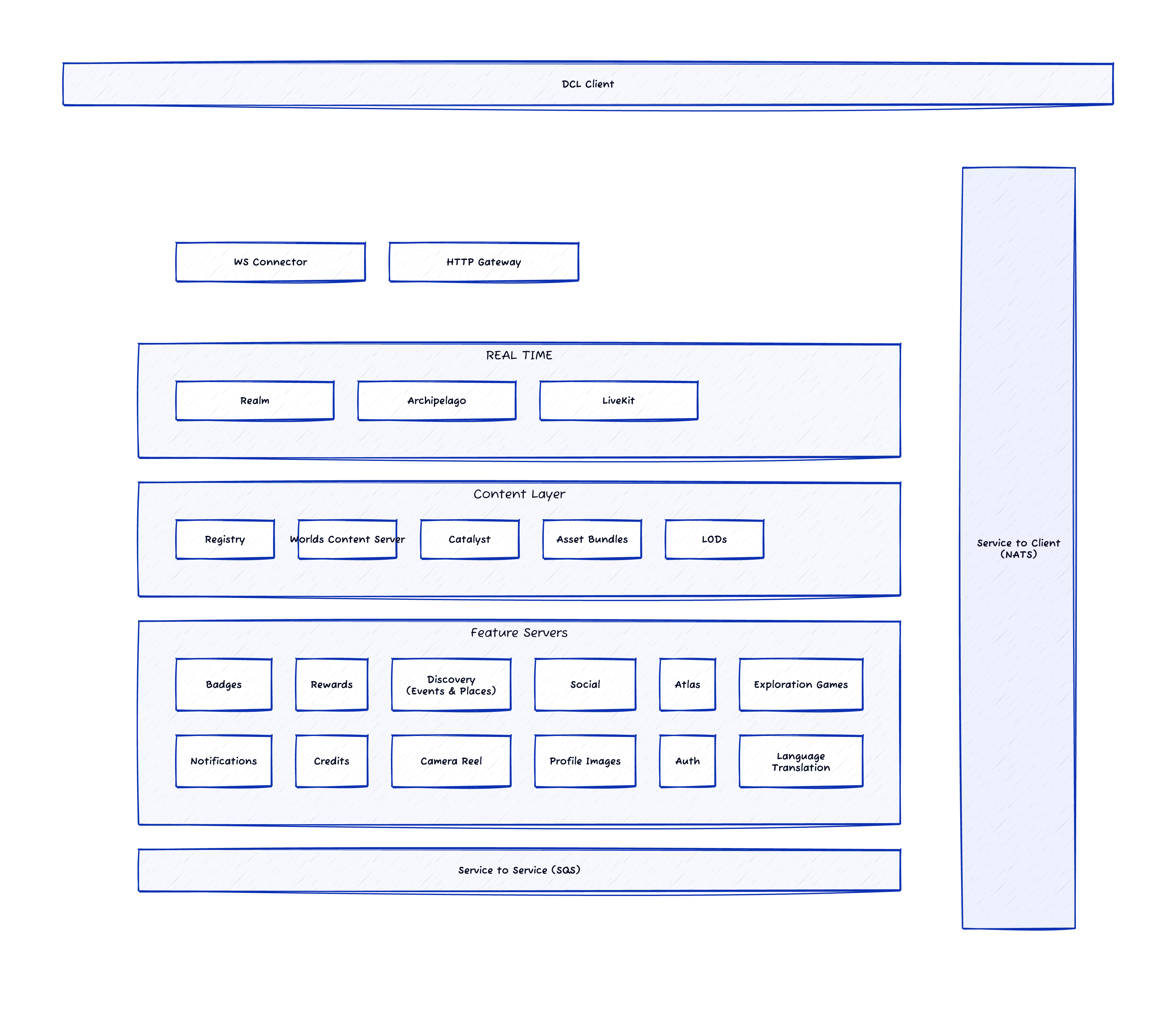
Now we can answer any question related to our codebase, plan any change or product feature, and shape product ideas with real technical feasibility and a roadmap grounded in the actual dependency graph. Not hallucinated. Not approximated. Grounded.
Where We Are Now
We're using Jarvis as a Slack app — anyone in the company can ask questions about the codebase and get accurate, context-aware answers. By treating Jarvis as our knowledge base, we built multiple skills into the Slack app so it can answer architecture questions and generate actionable plans. It can explain how to perform tasks (e.g., where to POST to update data), produce end-to-end implementation plans for new features based on product definitions, recommend where to place new services, account for libraries and dependencies, and follow our architectural guidance, coding standards, and principles for when to create versus reuse a service — including flagging potential conflicts with existing functionality. It can review pull requests and provide contextual feedback on implementation, style, and architectural fit, and it can intake product ideas and turn them into structured product implementation ideas.
But the real power is broader: you can start a fresh repo, install Jarvis, and ask an agent to do what you need with full awareness of how everything fits together.
What's striking is how much the AI landscape has shifted in just four months. In November 2025, we were working with chat-based assistants and expensive context windows. By March 2026, the tools caught up to what we'd been building toward. MCP became mainstream. Claude Code shipped Skills and custom commands. Cursor rolled out autonomous agent workflows. GitHub Copilot evolved into a full coding agent with Planning Mode. The shift from chat-based assistance to true agentic platforms happened faster than anyone expected.
The timing worked in our favor. We spent those months building the foundation — standards, documentation, schemas, a knowledge library — while the tools were maturing. Now those foundations compound. Every improvement to the AI tools amplifies the work we already did. The agents aren't just smarter; they have something real to work with.
This was a big effort by a lot of people. The kind of engineers who don't wait for permission to make things better. The kind who show up on a Thursday because they believe the codebase deserves it. All the cheers to them.
The best internal improvements don't need a place on the roadmap. They need a group of engineers who care enough to show up.